Secure Aggregation for Federated Learning
引言
本工作由keith等(google)完成发表在2016年nips上。对于联邦学习,隐私性与安全性是首要的,为此可以接受模型性能的轻微下降。Secure Aggregation(以下简称SA)是一类从分布式群体u∈U中获取统计量而不泄露单用户信息xu的方法。在这篇文章中,作者提出了用于保护联邦学习中分布式梯度更新的单个用户梯度的协议,这项协议在效率以及稳定性上都做了考虑,在至多三分之一用户未完成协议时仍然能保证安全性。
SA4FL
在标准的联邦学习算法中,客户端使用本地数据对本地模型参数计算一次梯度更新δtu=|Du|∇Lf(Du,Θt),这里Du为客户端u所持有的训练数据,服务器则汇总来自客户端的梯度计算平均值∇Lf(B,Θ)=1|B|∑u∈U′δtu,B=⋃u∈u′Du为从客户端群体子群包含训练集的并,并使用这个平均值更新全局模型。
尽管客户端上传的参数相比数据包含有更强的隐私性,在一些工作中表明了我们仍然可以使用模型参数重构训练样例,使用SA协议可以保证我们至多能够从全局模型中重构数据,而无法知道数据与客户端的对应关系。
Protocol 0: 单轮掩码保护
假定所有的客户端都完成协议,并且拥有充足带宽的成对安全交换通道,该协议分为如下几步:
- 用户u对其余用户v生成k维整数均匀分布随机向量su,v,用户u,v在安全信道交换各自的su,v,并计算扰动pu,v=su,v−sv,u. 注意有pu,v=−pv,u并规定u,v相等时pu,v=0;
- 用户u计算yu=xu+Σv∈Upu,v,并上传至服务器;
- 服务器汇总所有上传,计算ˉx=Σu∈Uyu,正确性由以下等式保证:
ˉx=Σu∈Uxu+Σu∈UΣv∈Upu,v=Σu∈Uxu+Σu∈UΣv∈Usu,v−Σu∈UΣv∈Usv,u=Σu∈Uxu.
以上为protocol 0的内容,它保证了用户u所拥有xu的完全隐私性,因为用户实际上传的yu包含了一项通过均匀采样产生的噪声,更重要地保证了服务器能够准确还原统计量ˉx. 实际上,即便服务器通过某些方式访问到部分u的xu值,这项协议仍然能保证剩余用户的信息安全性。
Protocol 1: 使用密信共享在含违协议用户情况还原统计量
protocol 0的问题在于,如果含有未将yu上传至客户端的用户,那么服务器将无法还原所需统计量。
为了保证协议的稳定性,我们首先增加一个初始轮次,每个用户u都会生成一个公私钥对,并通过配对通道广播公钥给其余用户。之后所有由u传至v的信息都由服务器中转,但是首先会用v的公钥加密,形成一条安全认证信道。这使得服务器始终能观察哪些用户成功完成协议的各个轮次。
在选定su,v后增加密信共享轮次,每个用户使用(t,n)−threshold scheme对每个pu,v都计算n个share,n为用户总数。简单说明一下(t,n)−threshold scheme的功能是将一个信息分成n份,使用其中不少于t份都可以还原信息,规定t>n2.
协议流程如下:
- 用户u生成公私钥对,通过用户间配对通道向其余用户广播公钥;
- 用户u对其余用户v生成k维整数均匀分布随机向量su,v,用户u,v在安全信道交换各自的su,v,并计算扰动pu,v=su,v−sv,u;
- 用户u对拥有的每个secret,即pu,v(v∈U)都计算其n个share,按照顺序依次用公钥加密后由服务器分发给其余用户v(每个v拿到的share都不同)。服务器记录参与secret share的用户群体,形成U的子集U1,要求|U1|≥t. 由于每个U1中的用户都收到了本集合中其它用户的share,故而知道U1所代表用户名单;
- 用户u计算yu=xu+Σv∈U1pu,v,并上传至服务器,服务器记录进行本次上传操作的用户,形成U1的子集U2(同样要求|U2|≥t);
- 服务器要求U2的每个用户u提供由U1∖U2发送的share,若U1,U2相同那么无需进行,考虑不同的情况(即有一部分用户没有上传yu),由于|U2|≥t,所以服务器能够还原这些secret: {pu,v|u∈U1∖U2,v∈U2},计算ˉx=Σu∈U2yu−Σu∈U2Σv∈U1∖U2pu,v,正确性由以下等式保证:
ˉx=(Σu∈U2xu+Σu∈U2Σv∈U1pu,v)−Σu∈U2ΣU1∖U2pu,v=Σu∈U2xu+Σu∈U2Σv∈U2pu,v=Σu∈U2xu
然而当服务器谎报U1∖U2时,单个用户的隐私就会被泄露,如服务器向U1∖U2减少特定用户uk,通过对比正确的ˉx与增加uk后计算的ˉx′就可以知道uk向xuk添加的噪声,从而获取xuk的值。
Protocol 2: 针对恶意服务器的双掩码保护
增加一轮掩码,服务器如果谎报则无法还原正确结果,也得不到任何有效信息。
首先每个用户u在生成su,v时均匀采样一个额外的随机k维向量bu,在secret share的阶段也将bu的share用公钥加密后由服务器中转给其余用户。
在产生yu时,用户同样将其作为掩码加入yu=xu+bu+Σv∈U1pu,v,在去掩码阶段服务器必须明确选择让U2的用户提供U1发送的su,v或bu的share其中之一,不能同时提供两者。
以单个U2中的用户u来说,对于u拥有的来自U1∖U2的share对(su,v及bu的share),服务器应该要求u提供su,v的share,剩余来自U2则应要求提供bu的share.
由于|U2|≥t,故而sever能够还原{bu,u∈U2},以如下方式计算最终统计量: ˉx=Σu∈U2yu−Σu∈U2bu−Σu∈U2ΣU1∖U2pu,v
Protocol 3: 高效交换密信
协议2虽然在正确选择t后可以保证稳定和安全,但需要O(kn2)的交流次数。
注意到使用单个数值与安全伪随机生成器就可以生成伪随机向量,用户可以只交换标量值su,v,bu然后作为种子扩张成k维向量。
这里使用钥协定来更有效率地建立这些secret,每个用户生成一个Diffie-Hellman密钥sSK与公钥sPK,然后将公钥上传至服务器,服务器将所有公钥广播给所有用户,并保留备份。
用户u,v通过如下方式确定各自su,v: su,v=sv,u=AGREE(SSKu,SPKv)=AGREE(SSKv,SPKu)
然后以如下方式计算扰动,假定U拥有全排序: pu,v=PRG(su,v),u<vpu,v=0,u=vpu,v=−PRG(su,v),u>v
protocol 3的安全性可以被证明与protocol 2一致
Protocol 4: 实践最小信任
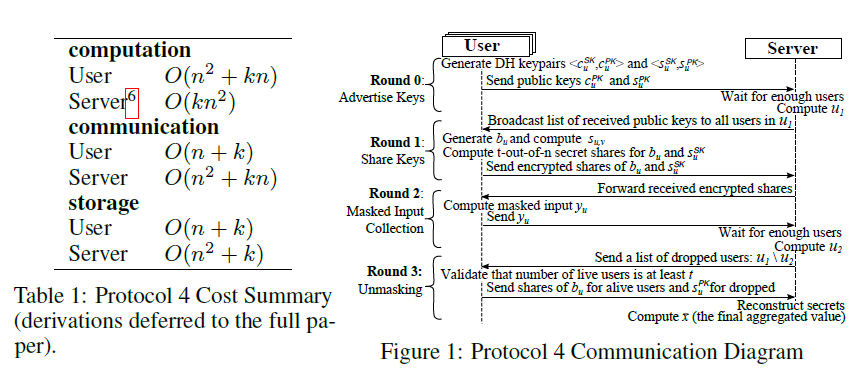
在上面的协议中,我们都假设用户间有安全的配对信道,需要给出更多细节。这里提出使用服务器中转密钥协议代替protocol 1描述的公私钥交换。
每个用户都会生成一个Diffie-Hellman密钥cSK以及公钥cPK,并将后者与sPK一起公布。
这里指出服务器有可能进行中间者攻击,但出于几个理由这是可以容忍的:
- 对于缺少认证机制的用户和预先存在的公钥架构这是不可避免的。只依赖联络阶段的非恶意性同样构成了信任最小:这一阶段的代码实现较短并且可以被空开编辑,向可信任第三方开源,或者通过一个能提供远程认证的可信计算平台来实现。
- 这项协议在其余层面提高了安全性(除了服务器进行中间攻击外),并且提供了正向保密性(在密钥交换后的任何时候入侵服务器,攻击者都不会得到有用信息,即便所有数据和会话都被记录下来)
图片给出了protocol 4各项复杂度以及流程
v1.5.2